

{kind=link}
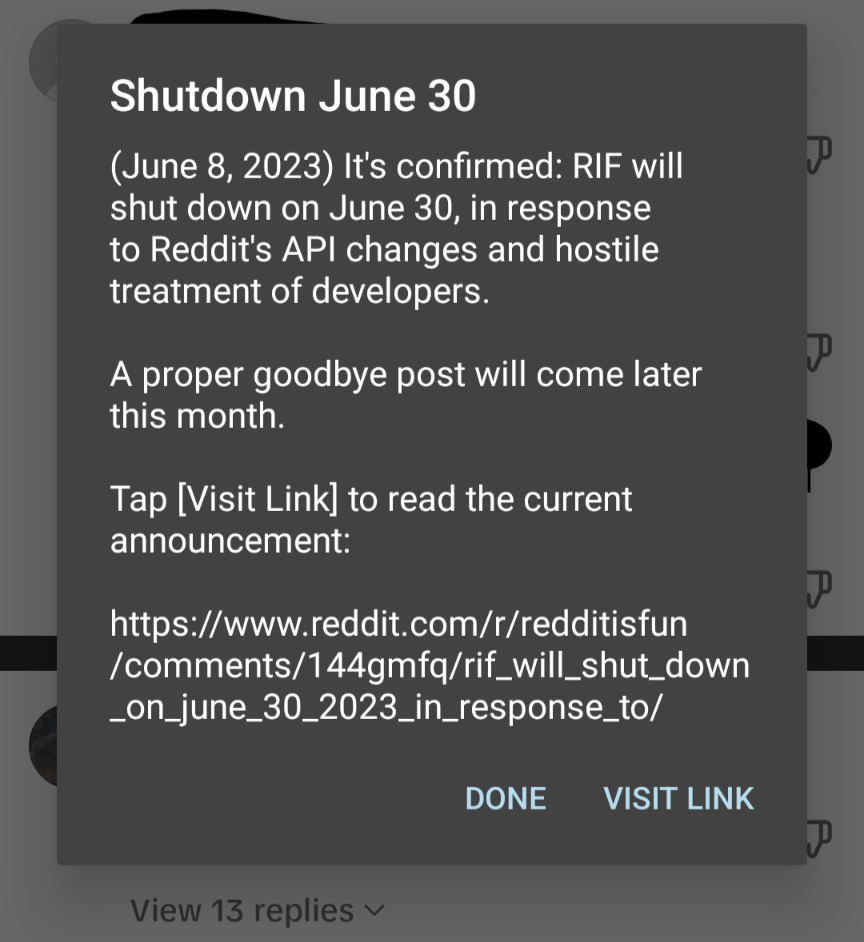
Reddit Is Fun was the only way I browsed Reddit on mobile. The mobile app is crap and doesn’t actually properly load posts. I get down a few scrolls and it ends like there isn’t anything else to view.
Reddit Is Fun was the only way I browsed Reddit on mobile. The mobile app is crap and doesn’t actually properly load posts. I get down a few scrolls and it ends like there isn’t anything else to view.
Too easy to scrape that data, the replies don’t update much after 2 days, and even then it’s pretty easy to re-scrape and check. And the data is not owned by reddit, its actually owned by their users. So if MS wants to scrape it, they need copyright permissions from the user, not reddit.
True, users do maintain copyright of anything they write, but they also give reddit license to use it how it wants, including sub-licensing it to others. That means the corps absolutely DO NOT need the permission of users to train their AI. They just buy the rights to use the data from reddit.
This includes images and videos that are uploaded to the reddit servers directly.
Reddit has the right to use the data and sell that data to others. Also, some data you can scrape, but there’s additional data that is available only through the API. Web scraping is not reliable, especially if reddit actively flags your spider and blocks it. They are not the idiots we want to believe they are. No mega corp is going to risk not having competitive access to data to feed their AIs when the cost for them to just pay is insignificant.
This shit was definitely not in the user agreement when I signed up in 2007.