It’s a different world now though. I could go into detail of the differences, but suffice to say you cannot compare them.
Having said that, Windows lately seems to just be slow on very modern systems for no reason I can ascertain.
I swapped back to Linux as primary os a few weeks ago and it’s just so snappy in terms of ui responsiveness. It’s not better in every way. But for sure I never sit waiting for windows to decide to show me the context menu for an item in explorer.
Anyway in short, the main reason for the difference with old and new computer systems is the necessary abstraction.
That’s complete nonsense I’m afraid. While abstractions are necessary, the bloat of modern software absolutely isn’t. A lot of the bloat isn’t fundamental, but a result of things growing through accretion, and people papering over legacy designs instead of starting fresh.
The selection pressures of the industry do not favor efficiency. Software developers are able to write inefficient software and rely on hardware getting faster. Meanwhile, hardware manufacturers benefit from bloated software because it creates demand for new hardware.
Phones are a perfect example of this in action. Most of the essential apps on the phone haven’t changed in any significant way in over a decade. Yet, they continue getting less and less performant without any visible benefit for the user. Imagine if instead, hardware stayed the same and people focused on optimizing software to be more efficient over the past decade.
Except it’s not nonsense. I’ve worked in development through both eras. You need to develop in an abstracted way because there are so many variations on hardware to deal with.
There is bloating for sure, and of course. A lot is because it’s usually much better to use an existing library than reinvent the wheel. And the library needs to cover many other use cases than your own. I encountered this myself, where I used a Web library to work with releases on forgejo, had it working generally, but then saw there was a library for it. The boilerplate to make the library work was more than I did to just make the Web requests.
But that’s mostly size. The bloat in terms of speed is mostly in the operating system I think and hardware abstraction. Not libraries by and large.
I’m also going to say legacy systems being papered over doesn’t always make things slower. Where I work, I’ve worked on our legacy system for decades. But on the current product for probably the past 5-10. We still sell both. The legacy system is not the slower system.
If I write software for fixed hardware with my own operating system designed for that fixed hardware and you write software for a generic operating system that can work with many hardware configurations. Mine runs faster every time. Every single time. That doesn’t make either better.
This is my whole point. You cannot compare the apollo software with a program written for a modern system. You just cannot.
I’m not disagreeing that it’s different. It’s a more fair comparison to compare it to embedded software development, where you are writing low level code for a specific piece of hardware.
I’m just saying that abstraction in general is not an excuse for the current state of computer software. Computers are so insanely fast nowadays it makes no sense that Windows file Explorer and other such software can be so sluggish still.
Exactly my point though. My original point was that you cannot compare this. And the main reason you cannot compare them is because of the abstraction required for modern development (and that happens at the development level and the operating system you run it on).
The Apollo software was machine code running on known bare metal interfacing with known hardware with no requirement to deal with abstraction, libraries, unknown hardware etc.
This was why my original comment made it clear, you just cannot compare the two.
Oh one quick edit to say, I do not in any way mean to take away from the amazing achievement from the apollo developers. That was amazing software. I just think it’s not fair to compare apples with oranges.
You’re making the fallacy of equating abstractions with inefficiency. Abstractions are indeed useful, and they make it possible to express higher level concepts easily. However, most of inefficiency we have in modern tech stacks doesn’t come from the need for abstraction. It comes from the fact that these stacks evolved over many decades, and things were bolted on as the need arose. This is even a problem at a hardware level now https://queue.acm.org/detail.cfm?id=3212479
The problem isn’t that legacy systems are themselves inefficient, it’s with the fact that things have been bolted on top of them now to do things that were never envisioned originally, to provide backwards compatibility, and so on. Take something like Windows as an example that can still run DOS programs from the 80s. The amount of layers you have in the stack is mind blowing.
Wait a second. When did I say abstraction was bad? It’s needed now. But when you are comparing 8bit machine code written for specific hardware against modern programming where you MUST handle multiple x86/x86_x64 cpus, multiple hardware combinations (either via the exe or by the libraries that must handle the abstraction) of course there is an overhead. If you want to tell me there’s no overhead then I’m going to tell you where to go right now.
It’s a necessary evil we must have in the modern world. I feel like the people hating on what I say are misunderstanding the point I make. The point is WHY we cannot compare these two things!
I didn’t say that you said abstraction was bad. What I said was that you’re conflating abstraction and inefficiency. These are two separate things. There is a certain amount of overhead involved in abstractions, but claiming that majority of the overhead we have today is solely due to the need for abstractions is unfounded.
Seems to me that you’re aggressively misunderstanding the point I’m making. To clarify, my point is that the layers of shit that constitute modern software stacks are not necessary to provide the types abstractions we want to have. They are an artifact of the fact that software grows through accretion, and there’s need for backwards compatibility.
If somebody was designing a system from scratch today it could both provide much better abstractions than we have and be far more efficient. The reason we’re not doing that is because the effort of implementing everything from scratch would be phenomenal. So, we’re stuck with taking older systems and building on top of them instead.
And on top of that, the dynamics of software development tend to favor building stuff that’s just good enough. As long as people are willing to use the software then it’s a success. There’s very little financial incentive to keep optimizing it past that point.
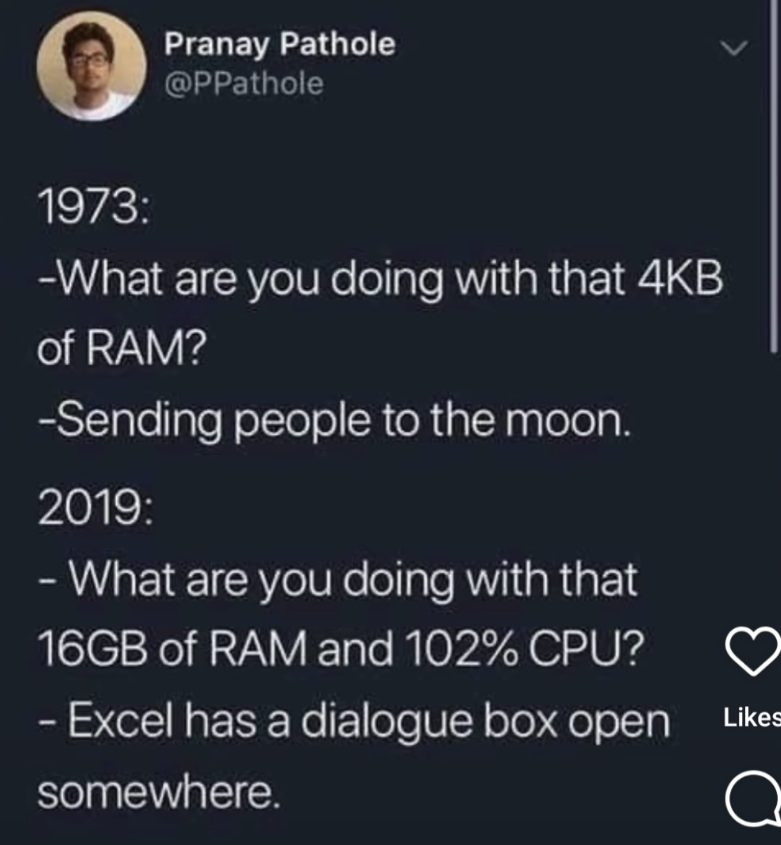
OK, look back at the original picture this thread is based on.
We have two situations.
The first is a dedicated system for providing navigation and other subsystems for a very specific purpose, with very specific hardware that is very limited. An 8 bit CPU with a very clearly known RISCesque instruction set, 4kb of ram and an bus to connect devices.
The second is a modern computer system with unknown hardware, one of many CPUs offering the same instruction set, but with differing extensions, a lot of memory attached.
You are going to write software very differently for these two systems. You cannot realistically abstract on the first system, in reality you can’t even use libraries directly. Maybe you can borrow code from a library at best. On the second system you MUST abstract because, you don’t know if the target system will run an Intel or Amd CPU, what the GPU might be, what other hardware is in place, etc etc.
And this is why my original comment was saying, you just cannot compare these systems. One MUST use abstraction, the other must not. And abstractions DO produce overhead (which is an inefficiency). But we NEED that and it’s not a bad thing.
The original picture is a bit of humor that you’re reading way too much into. All it’s saying is that we’re using computing resources incredibly inefficiently, which is undeniably the case. Of course, you can’t seriously make a direct comparison between the two scenarios. Everybody understands that.


{kind=link}
It’s a different world now though. I could go into detail of the differences, but suffice to say you cannot compare them.
Having said that, Windows lately seems to just be slow on very modern systems for no reason I can ascertain.
I swapped back to Linux as primary os a few weeks ago and it’s just so snappy in terms of ui responsiveness. It’s not better in every way. But for sure I never sit waiting for windows to decide to show me the context menu for an item in explorer.
Anyway in short, the main reason for the difference with old and new computer systems is the necessary abstraction.
That’s complete nonsense I’m afraid. While abstractions are necessary, the bloat of modern software absolutely isn’t. A lot of the bloat isn’t fundamental, but a result of things growing through accretion, and people papering over legacy designs instead of starting fresh.
The selection pressures of the industry do not favor efficiency. Software developers are able to write inefficient software and rely on hardware getting faster. Meanwhile, hardware manufacturers benefit from bloated software because it creates demand for new hardware.
Phones are a perfect example of this in action. Most of the essential apps on the phone haven’t changed in any significant way in over a decade. Yet, they continue getting less and less performant without any visible benefit for the user. Imagine if instead, hardware stayed the same and people focused on optimizing software to be more efficient over the past decade.
Except it’s not nonsense. I’ve worked in development through both eras. You need to develop in an abstracted way because there are so many variations on hardware to deal with.
There is bloating for sure, and of course. A lot is because it’s usually much better to use an existing library than reinvent the wheel. And the library needs to cover many other use cases than your own. I encountered this myself, where I used a Web library to work with releases on forgejo, had it working generally, but then saw there was a library for it. The boilerplate to make the library work was more than I did to just make the Web requests.
But that’s mostly size. The bloat in terms of speed is mostly in the operating system I think and hardware abstraction. Not libraries by and large.
I’m also going to say legacy systems being papered over doesn’t always make things slower. Where I work, I’ve worked on our legacy system for decades. But on the current product for probably the past 5-10. We still sell both. The legacy system is not the slower system.
Abstraction does not have to imply significant performance loss.
It does. It definitely does.
If I write software for fixed hardware with my own operating system designed for that fixed hardware and you write software for a generic operating system that can work with many hardware configurations. Mine runs faster every time. Every single time. That doesn’t make either better.
This is my whole point. You cannot compare the apollo software with a program written for a modern system. You just cannot.
I’m not disagreeing that it’s different. It’s a more fair comparison to compare it to embedded software development, where you are writing low level code for a specific piece of hardware.
I’m just saying that abstraction in general is not an excuse for the current state of computer software. Computers are so insanely fast nowadays it makes no sense that Windows file Explorer and other such software can be so sluggish still.
Exactly my point though. My original point was that you cannot compare this. And the main reason you cannot compare them is because of the abstraction required for modern development (and that happens at the development level and the operating system you run it on).
The Apollo software was machine code running on known bare metal interfacing with known hardware with no requirement to deal with abstraction, libraries, unknown hardware etc.
This was why my original comment made it clear, you just cannot compare the two.
Oh one quick edit to say, I do not in any way mean to take away from the amazing achievement from the apollo developers. That was amazing software. I just think it’s not fair to compare apples with oranges.
Dxvk would like a word
You’re making the fallacy of equating abstractions with inefficiency. Abstractions are indeed useful, and they make it possible to express higher level concepts easily. However, most of inefficiency we have in modern tech stacks doesn’t come from the need for abstraction. It comes from the fact that these stacks evolved over many decades, and things were bolted on as the need arose. This is even a problem at a hardware level now https://queue.acm.org/detail.cfm?id=3212479
The problem isn’t that legacy systems are themselves inefficient, it’s with the fact that things have been bolted on top of them now to do things that were never envisioned originally, to provide backwards compatibility, and so on. Take something like Windows as an example that can still run DOS programs from the 80s. The amount of layers you have in the stack is mind blowing.
Wait a second. When did I say abstraction was bad? It’s needed now. But when you are comparing 8bit machine code written for specific hardware against modern programming where you MUST handle multiple x86/x86_x64 cpus, multiple hardware combinations (either via the exe or by the libraries that must handle the abstraction) of course there is an overhead. If you want to tell me there’s no overhead then I’m going to tell you where to go right now.
It’s a necessary evil we must have in the modern world. I feel like the people hating on what I say are misunderstanding the point I make. The point is WHY we cannot compare these two things!
I didn’t say that you said abstraction was bad. What I said was that you’re conflating abstraction and inefficiency. These are two separate things. There is a certain amount of overhead involved in abstractions, but claiming that majority of the overhead we have today is solely due to the need for abstractions is unfounded.
Seems to me that you’re aggressively misunderstanding the point I’m making. To clarify, my point is that the layers of shit that constitute modern software stacks are not necessary to provide the types abstractions we want to have. They are an artifact of the fact that software grows through accretion, and there’s need for backwards compatibility.
If somebody was designing a system from scratch today it could both provide much better abstractions than we have and be far more efficient. The reason we’re not doing that is because the effort of implementing everything from scratch would be phenomenal. So, we’re stuck with taking older systems and building on top of them instead.
And on top of that, the dynamics of software development tend to favor building stuff that’s just good enough. As long as people are willing to use the software then it’s a success. There’s very little financial incentive to keep optimizing it past that point.
OK, look back at the original picture this thread is based on.
We have two situations.
The first is a dedicated system for providing navigation and other subsystems for a very specific purpose, with very specific hardware that is very limited. An 8 bit CPU with a very clearly known RISCesque instruction set, 4kb of ram and an bus to connect devices.
The second is a modern computer system with unknown hardware, one of many CPUs offering the same instruction set, but with differing extensions, a lot of memory attached.
You are going to write software very differently for these two systems. You cannot realistically abstract on the first system, in reality you can’t even use libraries directly. Maybe you can borrow code from a library at best. On the second system you MUST abstract because, you don’t know if the target system will run an Intel or Amd CPU, what the GPU might be, what other hardware is in place, etc etc.
And this is why my original comment was saying, you just cannot compare these systems. One MUST use abstraction, the other must not. And abstractions DO produce overhead (which is an inefficiency). But we NEED that and it’s not a bad thing.
The original picture is a bit of humor that you’re reading way too much into. All it’s saying is that we’re using computing resources incredibly inefficiently, which is undeniably the case. Of course, you can’t seriously make a direct comparison between the two scenarios. Everybody understands that.
Oh nice, coincidentally I was looking for that “C Is Not a Low-level Language” article yesterday.
it’s such a great read