The obvious easy solution would be to teach LLMs to guide the user through their “thinking process” or however you may call it. Instead of answering outright. This is what people do too, right? They look at what they thought and/or wrote. Or they would say “let’s test this”. Like good teachers do. Problem is, that would require some sort of intelligence, which artificial intelligence ironically doesn’t possess.
I would consider even LLMs actual AI. Even bots in video games are called AIs, no? But I agree that people are vastly overestimating their capabilities and I hate the entrepreneurial bullshitting as much as everyone else.
Those are all one token. A token can be a whole sentence. Tokenization tends to be based on LZW compression which combines common phrases (of any length, e.g. “Once upon a time” could be a single token because it’s recurring)
“Yes” is almost always followed by an explanation of a single idea while “It depends” is followed by several possible explanations.
I really hate that LLM stuff has been bazinga’d because it’s actually really cool. It’s just not some magical solution to anything beyond finding statistical patterns
Yes I recognize that it is very advanced statistical analysis at its core. It’s so difficult to get that concept across to people. We have a GenAI tool at work but I asked it a single question with easily verifiable and public data and it got it so wrong. It got the structure correct but all of the figures were made up
I think the best way to show people is to get them to ask it leading questions.
LLMs can’t deal with leading questions by design unless the expert system sitting on top of them can deal with it.
Like get them to ask why a very obviously wrong thing is right. Works better with very industry specific stuff that they haven’t programmed the expert system managing responses to deal with.
In my industry: “Thanks for helping me figure out my 1:13 split fiber optic network, what even sized cable would I need to make the implementation work?”
It’ll just refuse to give you an answer or it’ll give you no answer and just start explaining terms. When you get a response like that it’s because another LLM system tailored the response because of low confidence in the answer. Those are usually asked to re-phrase the answer to not assert anything and just focus on individual elements of the question.
My usual response is a list of definitions and tautologies followed by “I need more information” but that’s not what the LLM responded with. Responses like that are tailored by another LLM that’s triggered when confidence in a response is low.
This is “chain of thought” (and a few others based on “chain of thought”), and yes it gives much better results. Very common thing to train into a model. Chatgpt will do this a lot, surprised it didn’t do that here. Only so much you can do I suppose.
There are chain of thought and tree of thought approaches and maybe even more. From what I understand it generates answer in several passes and even with smaller models you can get better results.
However it is funny how AI (LLMs) is heavily marketed as a thing that will make many jobs obsolete and/or will take over humanity. Yet to get any meaningful results people start to build whole pipelines around LLMs, probably even using several models for different tasks. I also read a little about retrieval augmented generation (RAG) and apparently it has a lot of caveats in terms of what data can and can not be successfully extracted, data should be chunked to fit into the context and yet retain all the valuable information and this problem does not have “one size fits all” solution.
Overall it feels like someone made black box (LLM), someone tried to use this black box to deal with the existing complexity, failed and started building another layer of complexity around the black box. So ultimately current AI adopters can find themselves with two complex entities at hand. And I find it kind of funny.


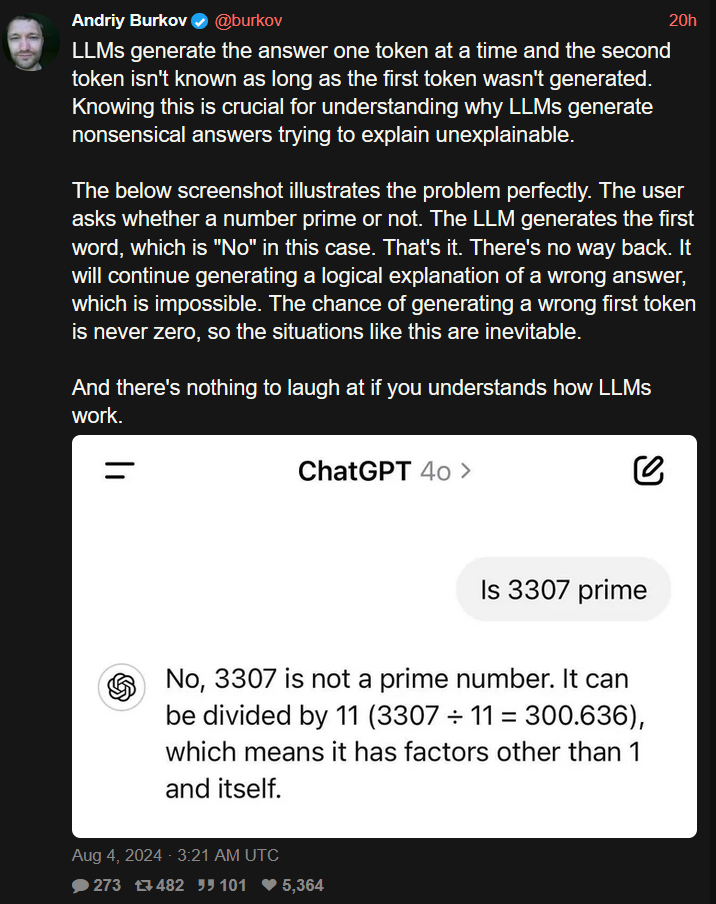{kind=link}
The obvious easy solution would be to teach LLMs to guide the user through their “thinking process” or however you may call it. Instead of answering outright. This is what people do too, right? They look at what they thought and/or wrote. Or they would say “let’s test this”. Like good teachers do. Problem is, that would require some sort of intelligence, which artificial intelligence ironically doesn’t possess.
It’s because AI is not an actual AI, it’s just marketing buzzwords
I would consider even LLMs actual AI. Even bots in video games are called AIs, no? But I agree that people are vastly overestimating their capabilities and I hate the entrepreneurial bullshitting as much as everyone else.
Machine learning! That was the better term.
It is, but it’s not in the way the marketing implies.
deleted by creator
How does this impact speed and efficiency vs 1 token?
Those are all one token. A token can be a whole sentence. Tokenization tends to be based on LZW compression which combines common phrases (of any length, e.g. “Once upon a time” could be a single token because it’s recurring)
“Yes” is almost always followed by an explanation of a single idea while “It depends” is followed by several possible explanations.
Oh that’s cool
I really hate that LLM stuff has been bazinga’d because it’s actually really cool. It’s just not some magical solution to anything beyond finding statistical patterns
Yes I recognize that it is very advanced statistical analysis at its core. It’s so difficult to get that concept across to people. We have a GenAI tool at work but I asked it a single question with easily verifiable and public data and it got it so wrong. It got the structure correct but all of the figures were made up
I think the best way to show people is to get them to ask it leading questions.
LLMs can’t deal with leading questions by design unless the expert system sitting on top of them can deal with it.
Like get them to ask why a very obviously wrong thing is right. Works better with very industry specific stuff that they haven’t programmed the expert system managing responses to deal with.
In my industry: “Thanks for helping me figure out my 1:13 split fiber optic network, what even sized cable would I need to make the implementation work?”
It’ll just refuse to give you an answer or it’ll give you no answer and just start explaining terms. When you get a response like that it’s because another LLM system tailored the response because of low confidence in the answer. Those are usually asked to re-phrase the answer to not assert anything and just focus on individual elements of the question.
My usual response is a list of definitions and tautologies followed by “I need more information” but that’s not what the LLM responded with. Responses like that are tailored by another LLM that’s triggered when confidence in a response is low.
This is “chain of thought” (and a few others based on “chain of thought”), and yes it gives much better results. Very common thing to train into a model. Chatgpt will do this a lot, surprised it didn’t do that here. Only so much you can do I suppose.
Didn’t wolfram alpha do this like 10 years ago?
There are chain of thought and tree of thought approaches and maybe even more. From what I understand it generates answer in several passes and even with smaller models you can get better results.
However it is funny how AI (LLMs) is heavily marketed as a thing that will make many jobs obsolete and/or will take over humanity. Yet to get any meaningful results people start to build whole pipelines around LLMs, probably even using several models for different tasks. I also read a little about retrieval augmented generation (RAG) and apparently it has a lot of caveats in terms of what data can and can not be successfully extracted, data should be chunked to fit into the context and yet retain all the valuable information and this problem does not have “one size fits all” solution.
Overall it feels like someone made black box (LLM), someone tried to use this black box to deal with the existing complexity, failed and started building another layer of complexity around the black box. So ultimately current AI adopters can find themselves with two complex entities at hand. And I find it kind of funny.