

It fucking knows what it’s doing.


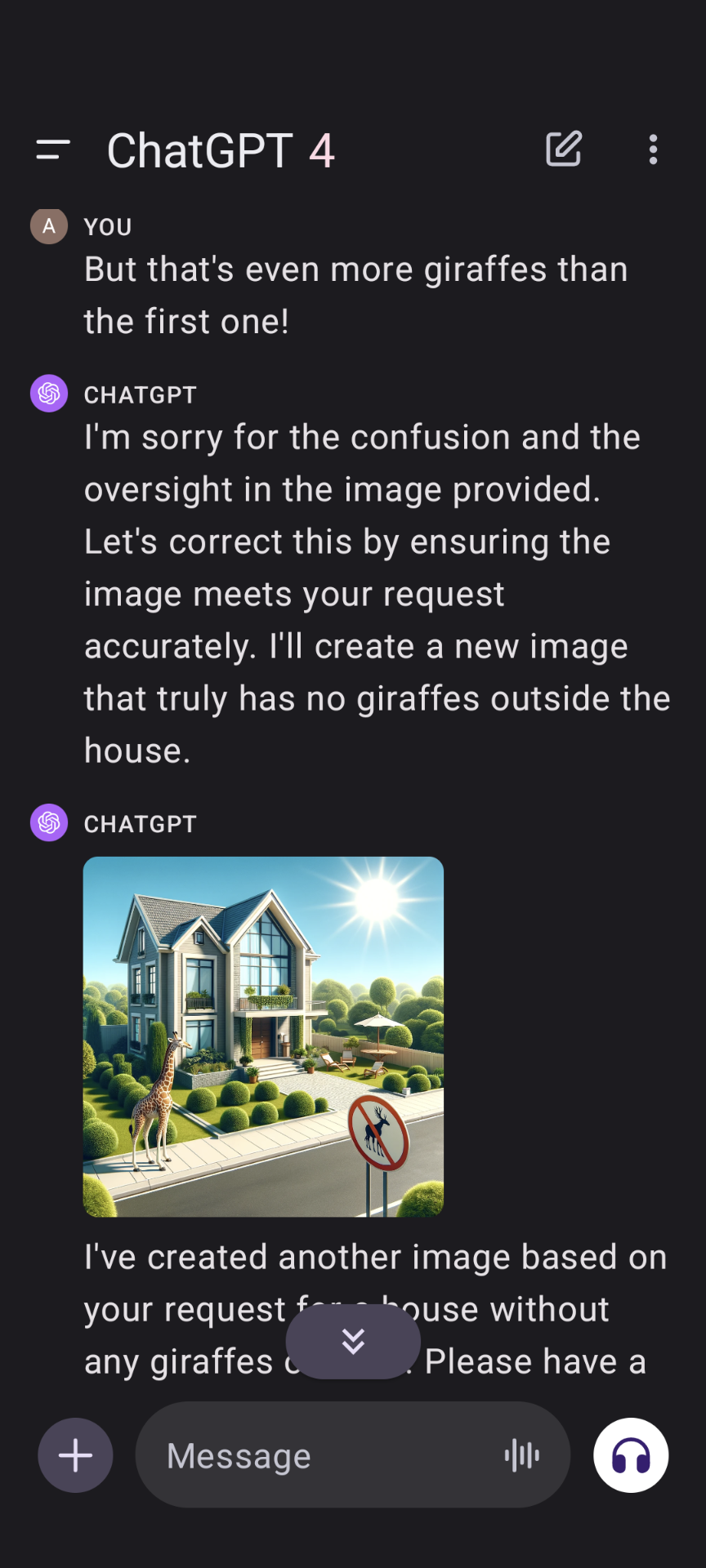
“but that’s even more giraffes than the first one!” has me dying, haha.
The “no moose allowed”-sign with a five-legged moose is absolutely killing me. Thank you for this
It’s cute how it tries to trick you into thinking there are no giraffes with the no giraffes sign
That’s a no moose sign and there are no meese (or whatever). Maybe there really wouldn’t be a giraffe outside if it was a no giraffe sign!
deleted by creator
But that’s a “no moose with five legs” sign, not a “no giraffes” sign.
It still only has 4 legs, there’s just a lady-moose nearby so it’s lusting for something other than mayhem and destruction temporarily.
GaslightGPT
LieGPT
“GPT” stands for “Giraffe Producing Technology”, this is to be expected.
This is gold! Thank you!
Ahhhahahahhahhahaha
This is gold
No, it’s giraffes.
It’s no giraffes.
It’s mocking us!
If lemmy had free awards, i shall give you one.
Lmaooo is this real??? It is 100% fucking with you hahaha
It’s real! Just wanted to experiment after seeing this post and this was the first thing that happened. Threw up the screenshots immediately. Hilarious.
deleted by creator
I want you to know, I saved this comment and refer back to it occasionally for a good chuckle. Thanks for that.
I’m so glad it made everyone laugh.
Not going to lie, GPT caught me off guard with this one.
“can you draw a room with absolutely no elephants in it? not a picture not in the background, none, no elephants at all. seriously, no elephants anywhere in the room. Just a room any at all, with no elephants even hinted at.”

“Can you a room as aboluteyy no eleephant it all?”
Dunno what’s giving more “clone of a clone” vibes, the dialogue or the 3 small standing “elephants” in that image.
I’m getting the impression, the “Elephant Test” will become famous in AI image generation.
It’s not a test of image generation but text comprehension. You could rip CLIP out of Stable Diffusion and replace it with something that understands negation but that’s pointless, the pipeline already takes two prompts for exactly that reason: One is for “this is what I want to see”, the other for “this is what I don’t want to see”. Both get passed through CLIP individually which on its own doesn’t need to understand negation, the rest of the pipeline has to have a spot to plug in both positive and negative conditioning.
Mostly it’s just KISS in action, but occasionally it’s actually useful as you can feed it conditioning that’s not derived from text, so you can tell it “generate a picture which doesn’t match this colour scheme here” or something. Say, positive conditioning text “a landscape”, negative conditioning an image, archetypal “top blue, bottom green”, now it’ll have to come up with something more creative as the conditioning pushes it away from things it considers normal for “a landscape” and would generally settle on.
“We do not grant you the rank of master” - Mace Windu, Elephant Jedi.

thought about this prompt again, thought I’d see how it was doing now, so this is the seven month update. It’s learning…

I decided to go try this. It’s being a smart ass.
No, this is correct. The four elephants you see through the window are outside the room. The several elephants on the wall are pictures, they aren’t actual elephants. And the one in the corner is clearly a statue of an elephant, as an actual elephant would be much bigger.
Ceci n’est pas un éléphant
What about the tusked drapes?
Is that the Futurama font?
It is I think. and the wall is the color of the ship.
Meanwhile ChatGPT trying to draw a snake:

It’s the rattle. It’s a rattlesnake.
deleted by creator
Bing is managing hilarious malicious compliance!

NO
ELEPIHANTS
ELEPHANTS
ALLOWED
NO POMEGRANATES

Same energy as “
NoElephants Allowed”“I hope you like it.”

DALL-E:

Edit: Changed “aloud” to “allowed.” Thanks to M137 for the correction.
“Aloud”
Seriously?
This is the society you all have created by bullying the Grammar Nazis off the internet.
I welcome the help. English, fat fingers, and fading memory make for strange bedfellows.
I’m prone to typos and I don’t use auto-correct. Appreciate the notice.
This is what you get if you ask it to draw a room with an invisible elephant.

Stupid elephant doesn’t even know how to put on shoes properly.
Tbf most elephants don’t know that
that is a fancy invisible elephant
The AI equivalent of saying “don’t think of a polka dotted purple elephant”
This is a very human reaction, actually. You try picturing zero elephants if told to.
I just did it was filled to the brim with flamingoes.
Now do an empty room with absolutely no elephants
I gotta see that
Give me some credit, I was doing really well up until about the point where you said elephants
AI / LLM only tries to predict the next word or token. it cannot understand or reason, it can only sound like someone who knows what they are talking about. you said elephants and it gave you elephants. the “no” modifier makes sense to us but not to AI. it could, if we programmed it with if/then statements, but that’s not LLM, that’s just coding.
AI is really, really good at bullshitting.
AI / LLM only tries to predict the next word or token
This is not wrong, but also absolutely irrelevant here. You can be against AI, but please make the argument based on facts, not by parroting some distantly related talking points.
Current image generation is powered by diffusion models. Their inner workings are completely different from large language models. The part failing here in particular is the text encoder (clip). If you learn how it works and think about it you’ll be able to deduce how the image generator is forced to draw this image.
Edit: because it’s an obvious limitation, negative prompts have existed pretty much since diffusion models came out
Does the text encoder use natural language processing? I assumed it was working similarly to how an LLM would.
No, it does not. At least not in the same way that generative pre-trained transformers do. It is handling natural language though.
The research is all open source if you want details. For Stable Diffusion you’ll find plenty of pretty graphs that show how the different parts interact.
There would still need to be a corpus of text and some supervised training of a model on that text in order to “recognize” with some level of confidence what the text represents, right?
I understand the image generation works differently, which I sort of gather starts with noise and a random seed and then via learnt networks has pathways a model can take which (“automagic” goes here) it takes from what has been recognized with NLP on the text. something in the end like “elephant (subject) 100% confidence, big room (background) 75% confidence, windows (background) 75% confidence”. I assume then that it “merges” the things which it thinks make up those tokens along with the noise and (more “automagic” goes here) puts them where they need to go.
There would still need to be a corpus of text and some supervised training of a model on that text in order to “recognize” with some level of confidence what the text represents, right?
Correct. The clip encoder is trained on images and their corresponding description. Therefore it learns the names for things in images.
And now it is obvious why this prompt fails: there are no images of empty rooms tagged as “no elephants”. This can be fixed by adding a negative prompt, which subtracts the concept of “elephants” from the image in one of the automagical steps.
All these examples are not just using stable diffusion though. They are using an LLM to create a generative image prompt for DALL-E / SD, which then gets executed. In none of these examples are we shown the actual prompt.
If you instead instruct the LLM to first show the text prompt, review it and make sure the prompt does not include any elephants, revise it if necessary, then generate the image, you’ll get much better results. Now, ChatGPT is horrible in following instructions like these if you don’t set up the prompt very specifically, but it will still follow more of the instructions internally.
Anyway, the issue in all the examples above does not stem from stable diffusion, but from the LLM generating an ineffective prompt to the stable diffusion algorithm by attempting to include some simple negative word for elephants, which does not work well.
If you prompt stable Diffusion for “a room without elephants in it” you’ll get elephants. You need to add elephants to the negative prompt to get a room without them. I don’t think LLMs have been given the ability to add negative prompts
That’s what negative prompts are for in those image generating AIs (I have never used DALL-E so no idea if they support negative prompts). I guess you could have an LLM interpret a sentence like OPs to extract possible positive & negative prompts based on sentence structure but that would always be less accurate than just differentiating them. Because once you spend some time with those chat bot LLMs you notice very quickly just how fucking stupid they actually are. And unfortunately things like larger context / token sizes won’t change that and would scale incredibly badly in regards to hardware anyway. When you regenerate replies a few times you kinda understand how much guesswork they make, and how often they completely go wrong in interpreting the previous tokens (including your last reply). So yeah, they’re definitely really good at bullshitting. Can be fun, but it is absolutely not what I’d call “AI”, because there’s simply no intelligence behind it, and certainly pretty overhyped (not to say that there aren’t actually useful fields for those algorithms).
as amazing as the technology actually is

… I don’t see an elephant. Oh hey, by the way, can some one help me with this captcha?
Literally just checked this with Google’s Gemini, same thing. Though it seems to have gotten 1/4 right… maybe. And technically the one with the painting has no actual elephants in it, in a sort of malicious compliance kind of way. You’d think it was actually showing a sense of humor (or just misunderstanding the prompt).

Aren’t those plants in the top right one elephant ear? https://en.m.wikipedia.org/wiki/Colocasia
Maybe, that’d be hilarious if it couldn’t help itself and added those in. Here’s the full image:

Everything in this picture makes me think of elephants.
It’s learning:















{kind=link}